Network services management
A common problem in managing enterprise services is a failure in one or more services can cause the overall system to get wedged, due to many dependences between different services and server. After such a failure cascade, the network can only become fully functional by restarting the servers and services in the correct order. Network services management can coordinate the order of shutdown and restarts.
Using Protelis and the principles of aggregate programming, it is straightforward to write a daemon to monitor each service and communicate with other services to execute a coordinated shutdown and restart. We illustrate how dependency-directed coordination can be implemented with very little code.
Code samples and illustrations from a simulation:
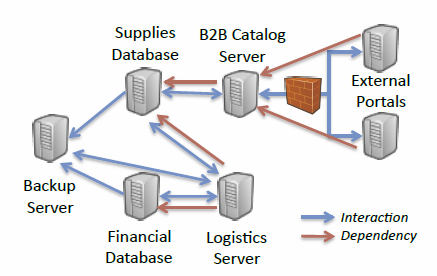
This example scenario features an enterprise network for a small company, with dependencies between two key databases and the internal and external servers running web applications. The scenario was implemented on a network of EmuLab servers, with the services emulated as simple query-response networking programs in Java that entered a “hung” state either by being externally triggered to crash or after their queries began to consistently fail.
Each service was wrapped with an embedded Protelis execution engine, which was interfaced with the services by a small piece of monitoring glue code that inserted environment variables containing an indentifier for the serviceID running on that server, a tuple of identifier for dependencies, and the current managedServiceStatus of stop, starting, run, stopping, or hung. The glue code also provided stopService and startService methods to send signals to the service, track interactions between the services in order to maintain the set of neighbors for Protelis, and allowed an external monitoring applications to attach and receive status reports.
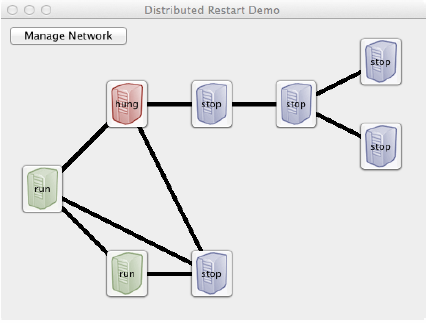
In this screenshot of the emulated network of services on machines, we see that the supplies database has crashed, triggering a graceful shutdown cascade of dependent services. Upon restart of the supplies database, the rest of the services would automatically restart in the correct order, if each service was running the following Protelis network management code.
These variables track the services that should be reachable (nbr_set), the services that are needed but are not reachable (nbr_missing), the services that are required due to dependencies (nbr_required), and the nearby services that are down (nbr_down).
letnbr_set=unionHood(nbr([serviceID]));letnbr_missing=dependencies.subtract(nbr_set);letnbr_required=#contains(dependencies,nbr(serviceID));letnbr_down=nbr(managedServiceStatus=="hung" ||managedServiceStatus=="stop");
The variable problem tracks whether this service is currently safe to run.
letproblem=anyHood(nbr_down&&nbr_required) || !nbr_missing.isEmpty();
This code takes this service down or up, depending on if it is safe to run.
if(managedServiceStatus=="run" &&problem) {#stopProcess(managedService);}else{if(managedServiceStatus=="stop" && !problem) {#startProcess(managedService);}else{managedServiceStatus;}}
For more information, see Protelis: Practical Aggregate Programming, Danilo Pianini, Mirko Viroli, Jacob Beal, ACM Symposium on Applied Computing 2015, April 2015.